
I’ve worked on a number of DevOps projects recently where I’ve had to assemble Continuous Delivery (CD) pipelines to build, deploy, and test software. In my case, we’ve been using Chef to automatically deploy various components of a java-based web system using Jenkins. We have a lot of pipeline job chains created in Jenkins to handle the various build, deploy, and test activities through a set of environments.
As part of a status review, I recently put together a matrix of a few component systems to compare how mature their CD pipelines were. Without having to actually read the elements on my blurry eye chart below, it ended up producing a picture that looked kind of like this:
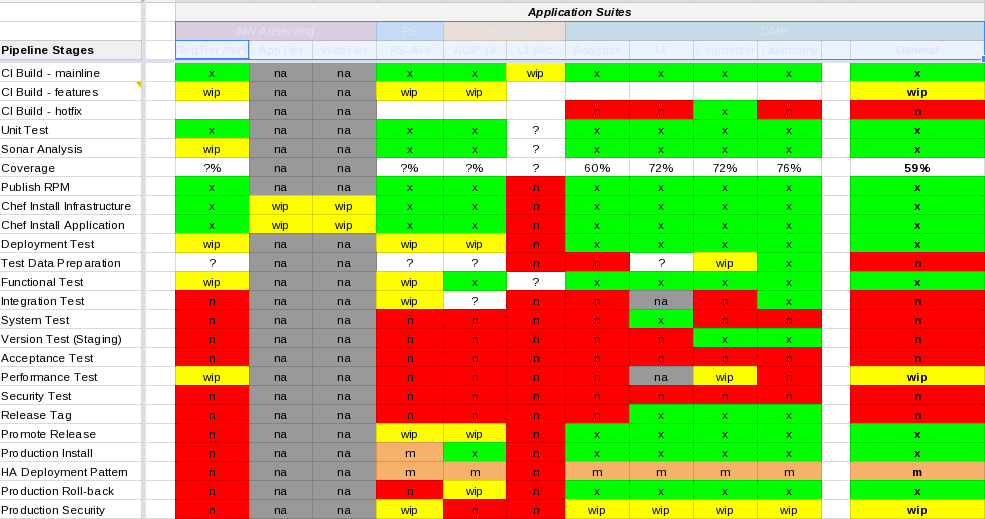
The left column indicates the various steps in the pipeline, starting at build, moving through testing, and finishing with secure production deployment. The columns across the top represent various software components that move through individual pipelines.
The important part was the colorization more than the text. The “maturity” of a component is indicated by the amount of green (or absence of red) in its column. Green indicates that we are in good shape with mature pipeline for the particular component. Red indicates something we need, but don’t have. Yellow indicates current work in progress. The Grey stuff is not applicable for the component in question. In some cases, I have little Orange ‘m’ blocks to indicate manual steps. White blocks fit squarely in the “I haven’t thought hard enough about this to know if we need it yet” area.
The chart forced me to think through some of the important “steps” that often appear in CD pipelines (the left column). You can read any book on CD or DevOps and they often give high level views (opinions?) of what some of those stages or steps should be. Here’s my take on what worked well for my current set of projects and might be useful for yours.
- CI Build (mainline) – build your software continuously as changes are committed to your repository. Use a “mainline” branch (master, develop, trunk, whatever) where everyone expects the main development branch to be, even if you use short feature branches to isolate and review small changes. This build ensures that the main development branch remains stable.
- CI Build (feature branches) – merge and build your feature branches into mainline on a continuous basis to ensure that the features do not diverge from the mainline of code.
- CI Build (hotfix branches) – ability to create and build a “hotfix” branch against current production software. This is often useful when you have a fairly slow release cycle where production lags current development streams, especially when your system consists of many independent system components.
- Unit Test – test your software implementation in isolated, non-deployed state using mocks or stubs for any integration points. Run these on a regular basis every time you commit a change to your software. Fail builds when unit tests fail.
- Static Analysis – use SonarQube or another tools to analyze quality metrics about your software. Run these on a regular basis when code changes are committed and fail builds when quality goals are not met.
- Code Coverage Analysis – use code coverage as a measurement of your unit tests. Fail builds when code coverage percentages do not meet goals.
- Package/Publish Configurable Software – produce a deployable package of software that can be installed in any environment: dev, qa, production, etc. This package should be externally configurable such that the same software can be installed and configured anywhere, as opposed to “compiling in” limited configurations that are hardwired for particular environments.
- Chef Install Application – use Chef recipes to install your software on target servers. Chef configures the app so it works in a particular environment. This will happen MOST often in your development environment, so it is most important of anything you do with deployment automation.
- Chef Install Infrastructure– use Chef to install all the other major software components that you depend upon (e.g., Java, Tomcat, Apache, MySQL). This allows you to take a clean machine and install everything necessary to make it a functional machine.
- Deployment Test – simple tests to validate that your Chef installation succeeded and the major services are functional. This might be checking that services are running, servers are responsive, or logs are being created. This is valuable to prove that installation succeeded and is not necessarily dependent on whether the software is functionally correct. It can also be done quickly.
At this point, you end up with deployed, running, testable software. The next step is really test it to the best extent possible. The following types of tests need to be done and may often overlap with one another. Regardless of whether this is one or many test suites, there are a variety of goals you need to accomplish during automated testing.
- Test Data Preparation – to properly test software, you often need to start with a certain “known” data set, process that data, evaluate that data, then potentially clean up any data you may have modified.
- Functional Test – test the software in an installed, deployed environment to validate that it provides all it’s functions. This testing is likely structured around the implementation of the features to make sure it provides all the services/features it is supposed to.
- Downstream Integration Test – does your software work properly in the presence of the components you depend upon. This replaces any mocked components you might have used in unit testing with real components which may exist on other servers and use real data sets.
- (Upstream) System Test – does the bigger system (that includes your newly modified component) function the way it is supposed to? That is, does an “integration test” against the system as a whole behave properly. This often requires testing the “upstream” components to verify that you provide the services they are expecting. Often the tests may be implemented or owned by other system component teams.
- Acceptance Test – does the system (your component along with others) provide the business-driven features that the customers expect. These are often cross-component scenarios that emulate what users actually do.
- Cross-Version Test – does your component work against both “latest and greatest development” as well as “production” versions of software. This provides confidence that the component can safely be installed in production in the presence of software versions that are older than the current development set.
- Performance Test – does the software meet it’s performance requirements? This can often be expressed as “absolute” metrics or “relative” metrics. Absolute metrics indicate that the software operating on hardware comparable to production performs in a certain manner. Relative metrics indicate that the software performs in a known environment in a consistent manner over time. That is, if the performance starts to degrade over time, then obviously the changes are slowing things down.
- Security Test – does the software meet it’s security goals? This often includes both requirements-based and risk-based testing activities. Requirements-based activities verify that users can perform the operations they are supposed to, and ONLY the operations they are supposed to. Risk based activities attack the system in various ways based on how the system is implemented and assembled.
Finally, as you approach releasable versions of your software, you often need additional release management activities to ensure that production software is traceable and managed properly to provide continuous user experience.
- Release Tagging – for releases going to production (or other environments), tag and trace the builds to source code and keep track of all necessary artifacts for traceability purposes. If production needs to be rebuilt for any reason, it can easily be reworked. In a automated Chef world, this may also involve capturing the versions of cookbooks that are used to install that software.
- Promote Release – capture and make a release package available in different environments (e.g., Dev, QA, Production). Whenever someone installs the component in that environment, this version becomes available.
- Production Deployment – actual installation into live Production environment. This is often a manually triggered step and may involve specific credentials or additional security. (See “Production Security” below.) Production deployment should also record other pieces of information, such as who did the deployment, the specific version of software deployed, when it was deployed. These logs should remain permanently available for traceability and auditing purposes.
- High-Availability Deployment Patterns – in production environments, it is often desirable to have “zero-down-time” deployments that provide continuous service. In these cases, it may be necessary to remove servers for a load balancer and upgrade the one at a time, or provide blue/green replacements, or follow some other pattern to ensure 100% up-time. In other environments, you can simply schedule a maintenance window to take the system down while it is upgraded.
- Production Roll-Back – ability to install a specific version of software (e.g., previous version) in the event of an aborted production release upgrade.
- Production Security – manage security properly between Dev and Production environments. This might not be a “step,” per se, but rather an adjustment to how existing steps operate. In many cases, you use Jenkins to push software deployments to various environments. If you use the same credentials to do this on all servers, that implies that people with access to “dev” servers might also have access to “prod” servers. This often means you need separate “root keys” that are used for encryption purposes as well as separate authentication credentials to actually log onto or control the boxes.
As you can see, this could involve having a LOT of steps in our pipeline for a particular software system. To complicate matters, you may need to consider whether these steps need to be repeated in different environments. Depending on whether you are using fixed/managed infrastructure machines or dynamic cloud machines you may also have additional provision and configuration steps. This also explains why one Jenkins server on my current project has almost 300 unique jobs. And that doesn’t include any manual steps that you might need for testing or other approvals along the chain.
Of course, your mileage my vary. On very simple projects, many of these CD steps may be irrelevant. On very complicated systems, you may have additional complications. Hopefully, this provides some frame of reference for evaluating what you need in your delivery pipeline.

