
Are you trying to shift from a monolithic system to a widely distributed, scalable, and highly available microservices architecture? Maybe you’ve already moved to agile delivery models, but you’re struggling to keep up with the rate of change in the technologies of these systems.
Meanwhile, your DevOps team has thrown a bunch of automation in place to help, but it seems to be creating a bigger, different mess that results in broken systems that don’t work together.
To succeed, you need to properly design and implement your delivery process with the right technology stack to support your software architecture, then structure teams around that process. At Coveros, we call this “DevOps engineering.”
Here’s how our teams assembled Kubernetes, Docker, Helm, and Jenkins to help produce secure, reliable, and highly available microservices.
The Microservices Design Challenge
I have yet to find an organization that has ended up with an ideal, perfectly designed set of microservices. They start out with the right intentions: “Let’s take all our busted monolithic systems and split them up!”
Doing this requires a delicate combination of technical architecture, automation, testing, and a development methodology, all closely related to agile and DevOps. If you don’t get the mix right, things rarely go as well as you planned.
When managing microservices in the real world, you can end up with a set of federated services with hidden dependencies, not-so-loosely coupled interfaces, and different rates of change, ranging from never to hourly. And these services must all be wired together to work properly.
To make matters worse, the teams that own them don’t talk to each other. Instead, they hide behind their poorly defined APIs. Teams use inconsistent technology stacks with different languages, frameworks, tools, and processes. And while this permits creative and technical freedom, it becomes very difficult to wrangle them together and build a cohesive product for your enterprise.
You have all these services changing at different rates that must be constantly built, deployed, and tested together across many environments to offer actual value to your end users and customers.
The Delivery Pipeline
At the core of your success lies your delivery pipeline, which defines your organization’s delivery process. The software delivery process is automated through a continuous integration/continuous delivery (CI/CD) pipeline to deliver application microservices into various test (and, eventually, production) environments.

A pipeline goes through three distinct stages. The CI stage is responsible for compiling, testing, and packaging your source code so it can be successfully installed in test environments. In many cases, you need to use a battery of tools to scan, unit-test, and otherwise assess the quality of the code for each of your microservices before moving it to the next stage.
During the CD phase, you take that packaged software bundle and start installing it into test environments somewhere. This typically involves provisioning some kind of server to install it on, install the microservice, and configure it so it can talk to other microservices.
Then you test it, a lot, in isolation and in combination with other services. Assuming it holds up, you promote your microservice to different environments, where it gets exposed to other batteries of tests: dev, test, QA, performance, staging, pre-production, and whatever else you call it.
Eventually it lands in production, and somewhere along the line, you enter the continuous monitoring phase. This is where you ensure that the software continues to run properly, using tools such as log aggregating, performance monitoring, scanning, etc., to find and fix anything that has operational issues.
Throughout this process, keep in mind that you have many microservices, all with their own source code base. You effectively have one of each of those complicated pipelines for each of your services. Each of these will run in parallel based on the rate of change for the services.
Furthermore, at some point they probably join because you need to test the services together before you can approve or ship a particular change. Doing all these builds at the same time can be very resource-intensive, and you’re going to need computational resources to support it.
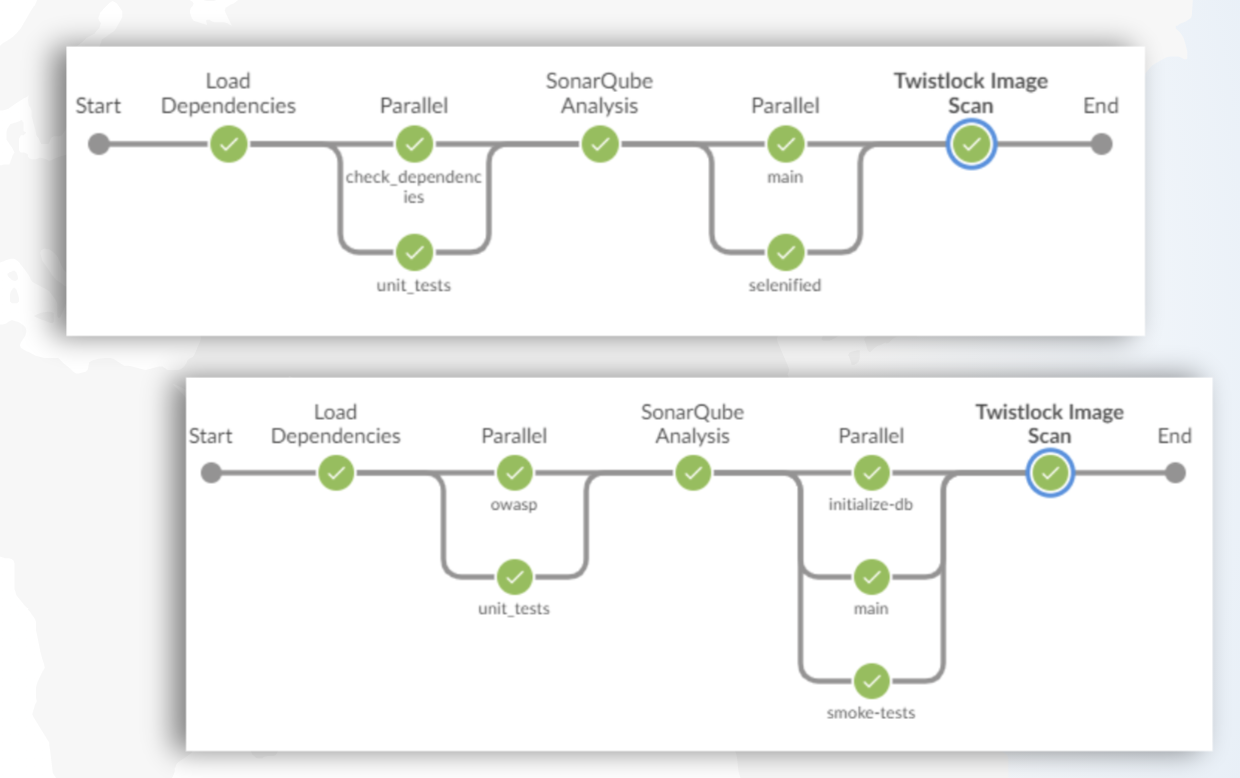
How Containers Can Help You
This is where the concept of containers comes into play. Microservices typically vary in fundamental ways. They are owned by different teams, change at different rates, are built with different languages and frameworks, and often use different tooling to build and test. Furthermore, they might depend on different versions of shared dependencies (i.e., Java 8 vs. Java 12), maybe run on different operating systems, and often have different resource or scaling needs.
Container technologies such as Docker build fully assembled, lightweight application images that have everything they need to run in an isolated environment on a server somewhere. This means your application container image gets built with the exact version of Java you need, doesn’t conflict with anyone else’s version, and can be granted exactly the amount of CPU, RAM, and storage you need to run your app.
In the world of application development and DevOps, we use containers in a variety of ways. First, we use containers as tools. As an example, we use Jenkins as our build server. For every build, Jenkins launches a “Jenkins agent” Docker container and can subsequently launch more Docker containers for any tools it might need: maven, gradle, npm, Selenium … whatever.
This provides easy scaling with the exact versions of the tools we need without having to install a bunch of plugins and other custom configurations. Even better, it allows our developers to use the exact same versions of tools the build pipeline does.
Second, we use containers in our infrastructure. All of our monitoring and logging tools run as containers and are easy to launch, scale, and upgrade. Our security services, including single sign-on, auditing tools, and other scanning tools, run as containers for the same reason.
Finally, we use containers for deployment production. That means our pipeline assembles containers that can be launched as independent services and integrated into our enterprise product. One nice thing is that the use of containers does not have to be all or nothing. You can start migrating some containers, then expand over time as you containerize your other services.
At some point, managing large groups of microservices (and supporting infrastructure) across many test and production environments requires complex configuration and orchestration. That’s where Kubernetes comes in.
Enter Kubernetes
Kubernetes is a highly scalable, self-healing, cost-efficient platform that enables you to build and deploy complex enterprise systems in flexible configurations. It allows you to capture the relationships among the various components of your microservices so they can all operate together.
In Kubernetes, you maintain a “cluster”—a group of servers that work together to host all the containers you run.
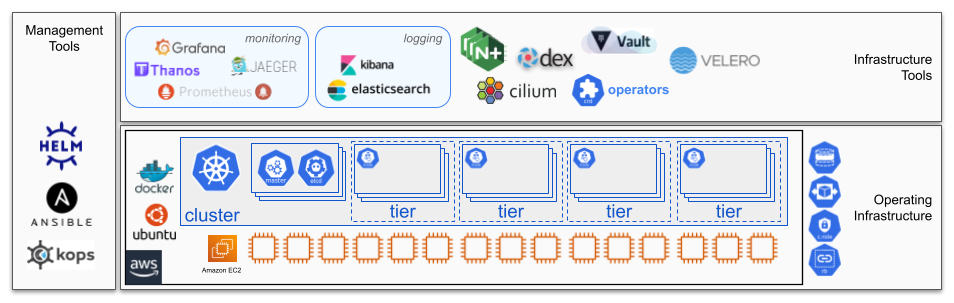
We use Kubernetes to maintain a standard set of clusters that all have a standard set of infrastructure tools running on top of them. This infrastructure provides the base for where all of our custom enterprise applications can run. It is also where we run our standard DevOps tool chain (Jenkins, SonarQube, Nexus, Selenium, Vault, etc.), which implements the delivery pipeline for all of our microservices.
To run our microservices in Kubernetes, we use the Helm packaging system to capture all the configuration information necessary to deploy one or more services together. Helm uses templates to represent configurable resources such as container deployments, service load balancer endpoints, ingress host addresses, secrets, and configuration settings presented as a chart.
At runtime, we install the Helm chart with a set of values that provide the unique settings needed for each service in each environment. Those value settings are stored in a dedicated cluster-state GitHub repository and include a list of all the version specifiers for each service in a particular environment.
This allows us to maintain differences—scaling limits, amounts of CPU/RAM, external configuration addresses, etc.—across all the environments in the enterprise. Furthermore, we use a GitOps approach with the cluster-state repository that automatically detects when a setting such as version number changes; this automatically triggers a new deployment update in the environment.
One of the most amazing side effects of all this infrastructure as code is that it becomes much easier to launch dynamic, on-demand test environments.
On my most recent project, we set up a self-service Jenkins job that allowed any user to create a complete production-like test environment in less than 15 minutes. This allows developers, testers, and even business analysts to run their own copy of the entire software system to test things, run experiments, or demonstrate functionality to others.
People are key
Through this process, we’ve learned that one of the most important factors for success lies in the teams and the people. Although the teams own their own services and live by their own rules, they are still likely to be part of an overall enterprise organization. As such, they need to work together and not hide behind their service APIs. Communicate. Remember: It’s about shared success.
Finally, embracing containers and technologies such as Kubernetes and Helm will force the developers, testers, technical operations, and even leadership teams to learn new technologies. Even if your operations team leads the charge, the development teams will absolutely need to learn and understand how Docker, Helm, and Kubernetes all work together.
You will definitely need some central expertise to help out, but don’t just build a DevOps team silo between your dev and ops groups and dump all the work on them.
Microservices are a great improvement in the way developers build software, but they come with their own set of troubles. Here are a few parting thoughts to keep in mind:
- Your CI/CD pipeline will become critical to delivering your software, and it’s going to become far more complicated over time. Microservices change fast and frequently. You won’t survive without a heavy dose of automation.
- Containers are the (near) future. If you have not started learning about and using containers, start now. You don’t have to go whole hog at first. Get your developers and ops folks using containers as tools. Start building some custom containers. Then look at containerizing your applications.
- Platforms such as Kubernetes will force you to write a lot more infrastructure as code, but it’s mostly in YAML and not really that hard. A big plus: Version-controlling all this makes it easy to automate, although that in itself requires more code. Be prepared to test and retest everything often.
- Above all, don’t forget that you are a team. Work together across services and across skill domains. Don’t build more silos of developers, testers, or ops people that refuse to talk to each other.

